 Speed up your innovation with Glows.ai, Scale up your large model training
Speed up your innovation with Glows.ai, Scale up your large model training Glows.ai Auto Deploy 使用案例
使用GPU部署服務通常需要我們手動創建實例,在使用完畢後還得手動釋放實例,如果比較零散使用GPU服務,這種模式操作起來就會比較繁複。
Glows.ai 提供了 Auto Deploy 服務,配置好 Auto Deploy 後會有一個固定的服務link,有請求發送到服務link,Glows.ai會根據我們的配置自動創建實例,然後處理請求並返回處理結果;在連續 n 分鐘沒有新請求發送到 link 的時候,Glows.ai 會自動幫我們釋放實例。
接下來讓我們一起具體使用下這個功能。本案例將以 BreezyVoice WebUI 鏡像為例子演示 Auto Deploy 使用方法。
目前支持自定義 Instance Idle Retention Period 和 Maximum Number of Instances。
- Instance Idle Retention Period:實例在無請求後,自動釋放時間
- Maximum Number of Instances:單個 Auto Deploy 支持啟動的最大實例數
在兼容之前調用處理邏輯的場景下,還另外還支持 Random 和 Round Robin 模式(這部分使用說明請看高級用法部分。
基礎用法
配置 Auto Deploy
進入 Auto Deploy 界面,點擊右上角的 New Deploy,新建一個配置項。
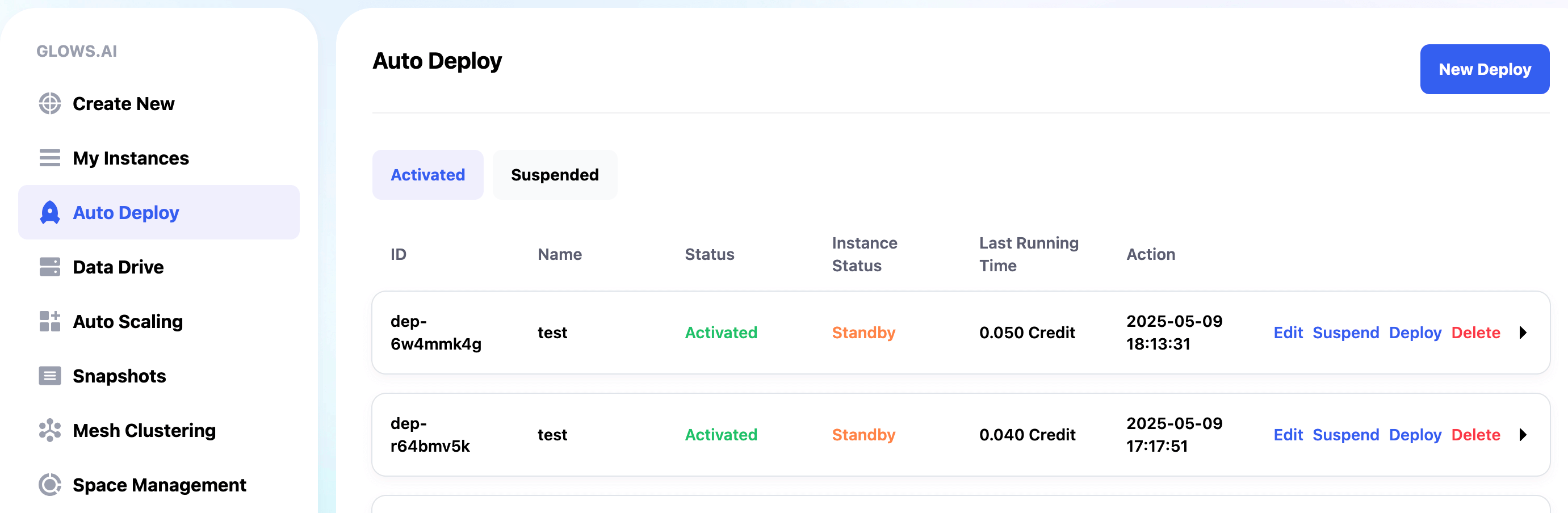
設置配置項名稱和簡介,方便自己區分。

選擇程序運行需要的顯卡和環境,可以選自己配置好的 Snapshot,也可以選系統預置的鏡像。
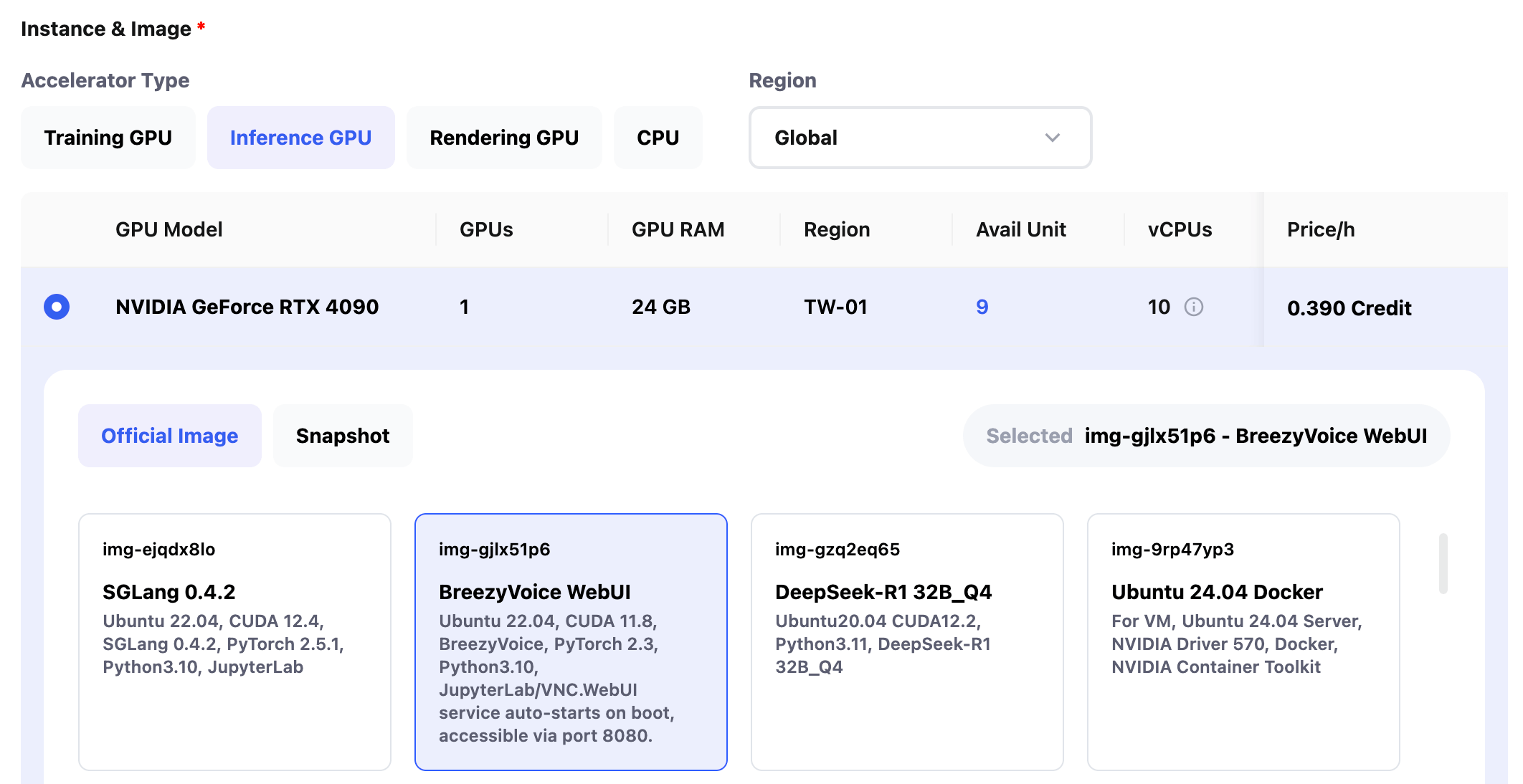
設置我們程序碼監聽的服務端口(Port)和程序碼運行指令(Start Command)。
本案例中,我們的服務啟動在 8080 端口,服務程序碼是 /BreezyVoice 目錄下的 api.py,所以服務端口和啟動指令設置如下。
Port: 8080
Start Command: cd /BreezyVoice && python api.py
另外設置 Instance Idle Retention Period 為 10min,設置 Maximum Number of Instances 為5。
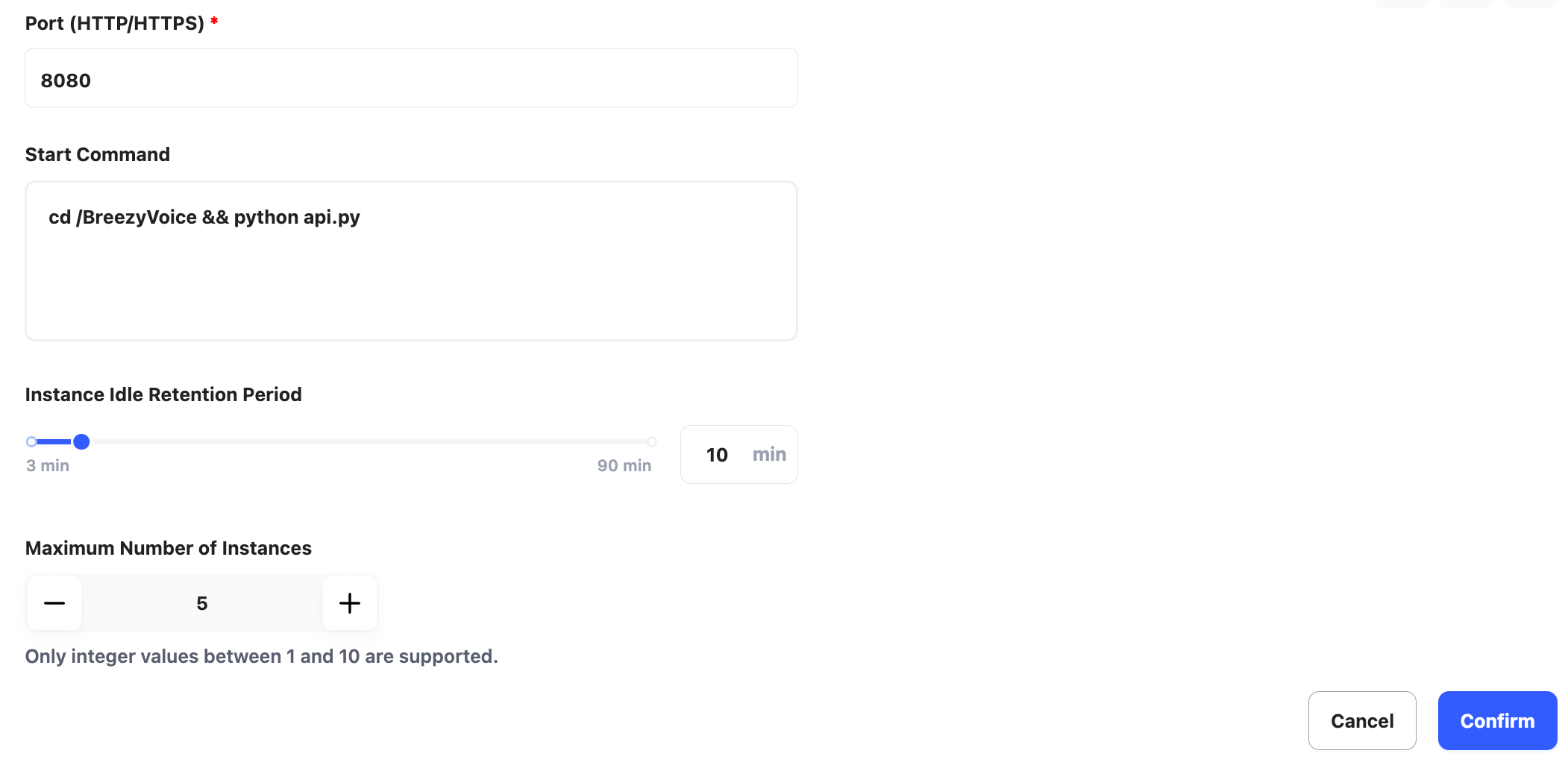
最後點擊 Confirm 完成配置。
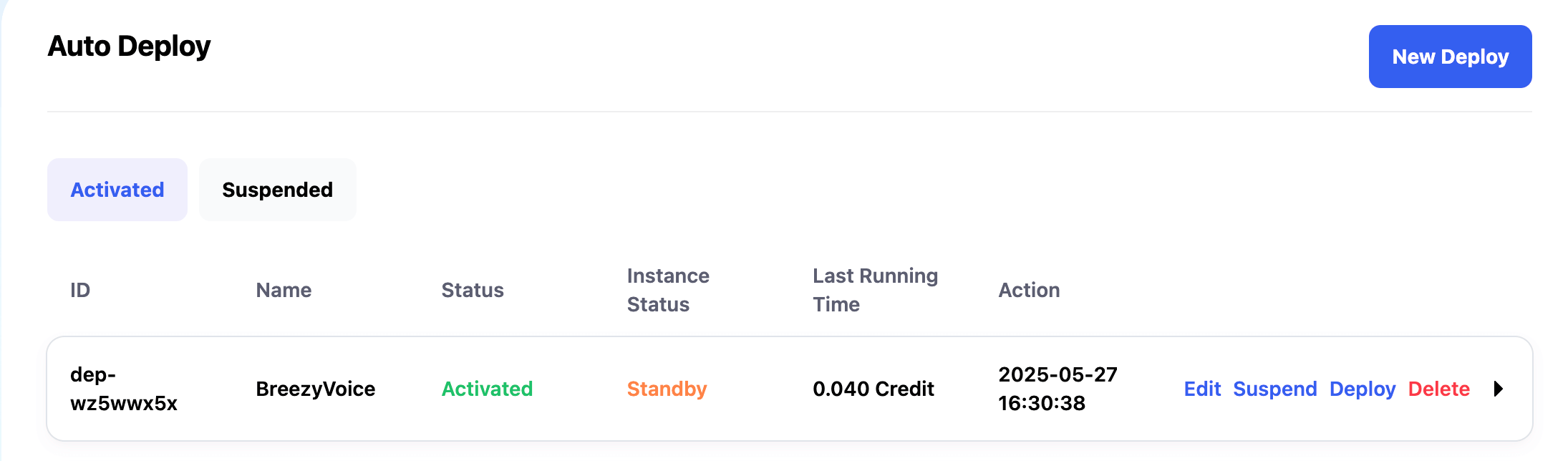
查看配置訊息
配置完成後即可看到服務對應的固定 link,以及我們配置的信息。
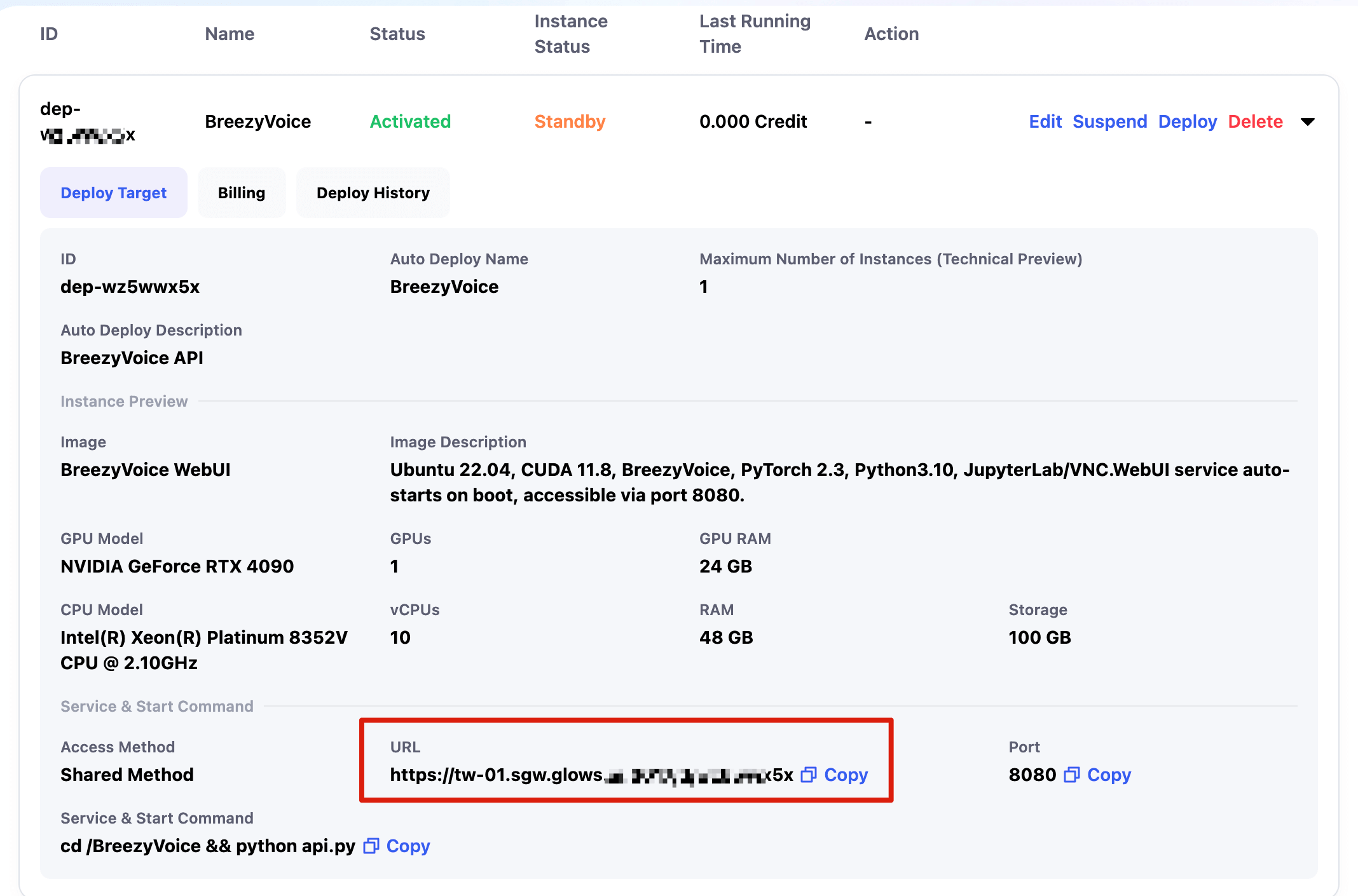
調用Auto Deploy link
API link 換成 Auto Deploy link即可,如果服務有自己的路由,請在 Auto Deploy link 後添加相關路徑,比如我部署的服務API請求路徑是 /v1/audio/speech。
curl -X POST "https://tw-01.sgw.glows.ai:xxxxxx/v1/audio/speech" \
-H "Authorization: Bearer sk-template" \
-H "Content-Type: application/json" \
--data '{
"model": "tts-1",
"voice": "alloy",
"input": "放學我們一起去打籃球怎麼樣,今天天氣不錯"
}' --output test_speech.wav

在請求結束後,10分鐘內我們不向API發送請求(創建時設置的 Instance Idle Retention Period 值),則機器會自動釋放,在 Auto Deploy 中也會顯示配置項目總花費,和Instance Status 狀態,Instance Status狀態含義如下:
-
Standby:表示配置正常,沒有在運行的實例。
-
Idle:收到請求時,表示實例創建中;請求處理完畢後,表示自動釋放實例中。
-
Running:實例創建成功,在處理請求,請求處理完成後會繼續等待新請求,如果連續5分鐘沒有新請求進入,則會自動釋放實例。
高級用法
在兼容之前調用處理邏輯的場景下,還另外還支持 Random 和 Round Robin 模式。可以在請求頭中設置 Deploy-Route-Rule 參數,支持以下值:
1> scale-out : 啟動一個新實例,並返回接口調用結果。
- 如果已啟動實例總數等於 Maximum Number of Instances 時再調用,會返回錯誤代碼:
{"code": 1007, "msg": "deployment replica quota exceeded"}
2> random : 隨機選擇一個已經啟動實例轉發請求,並返回接口調用結果。
- 如果沒有正在運行實例,會返回錯誤代碼:
{"code": 1006, "msg": "route target not found"}
3> round-robin : 將請求按順序流轉給已啟動實例,並返回接口調用結果。
- 如果沒有正在運行實例,會返回錯誤代碼:
{"code": 1006, "msg": "route target not found"}
4> {Deploy-Route-Target} : 將請求轉發給指定的實例,並返回接口調用結果。
- 如果沒有找到對應 Deploy-Route-Target,會返回錯誤代碼:
{"code": 1006, "msg": "route target not found"}
以上四種模式下,響應頭中都會顯示 Deploy-Route-Target,表示當前請求轉發到哪個實例上,方便有連續請求需要的用戶使用。
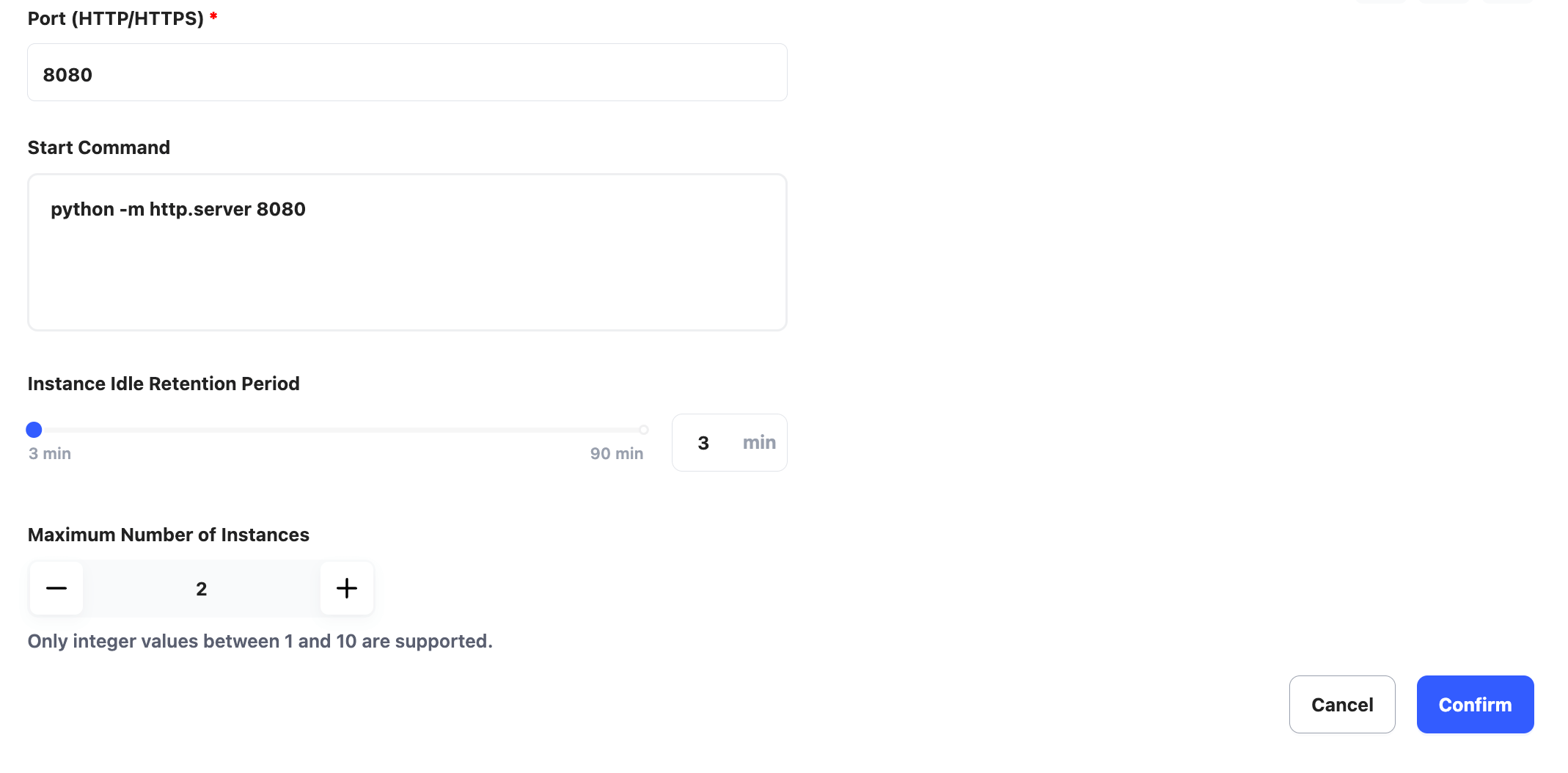
以下案例中,我們的服務啟動在 8080 端口,使用 Python 創建一個 HTTP Server,所以服務端口和啟動指令設置如下。
Port: 8080
Start Command: python -m http.server 8080
另外,設置 Instance Idle Retention Period 為 3min,設置 Maximum Number of Instances 為 2。
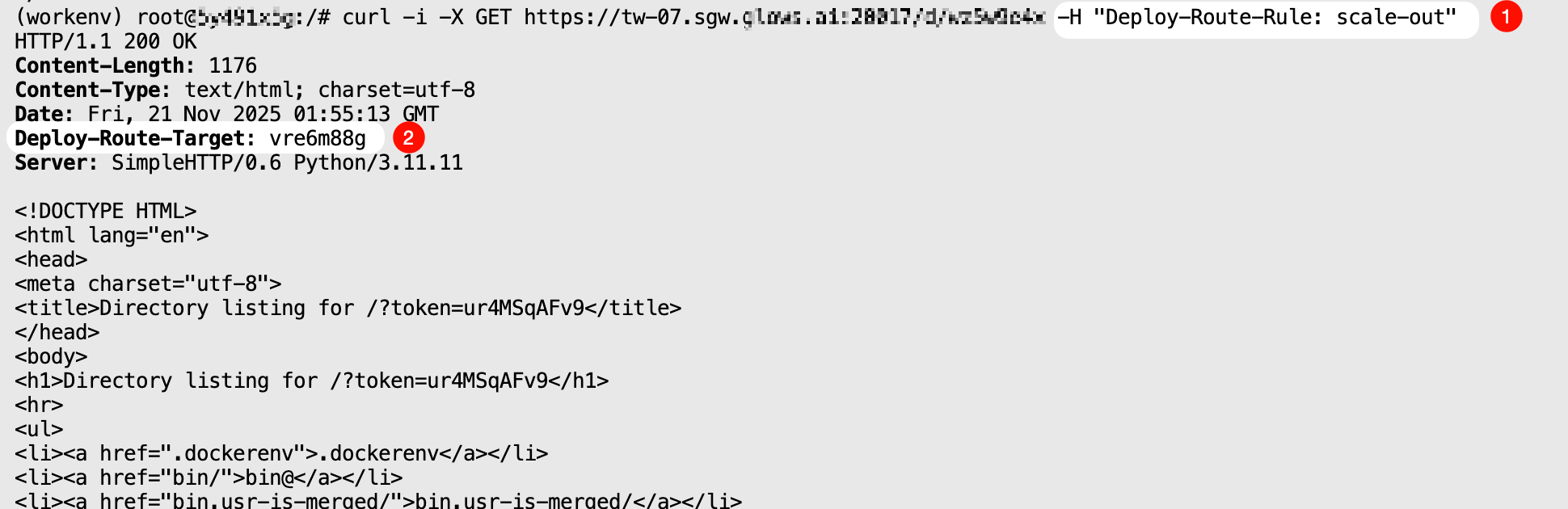
scale-out 模式
調用該模式會開啟一個新實例,並返回接口請求結果。
curl -i \
-X GET "https://tw-07.sgw.glows.ai:20017/d/xxxxx" \
-H "Deploy-Route-Rule: scale-out"
在響應頭中會顯示 Deploy-Route-Target 值,這個值對應我們實例介面看到的實例ID,後面也可以通過指定 Deploy-Route-Rule 為實例 ID,直接調用對應實例內服務。
需要注意,如果通過該 Auto Deploy 開啟的實例總數已經等於設置的 Maximum Number of Instances ,再調用該模式,會返回錯誤代碼:{"code": 1007, "msg": "deployment replica quota exceeded"}。
random 模式
從通過該 Auto Deploy 已開啟的實例中,隨機選擇一個實例轉發請求,並返回接口調用結果。
curl -i \
-X GET "https://tw-07.sgw.glows.ai:20017/d/xxxxx" \
-H "Deploy-Route-Rule: random"
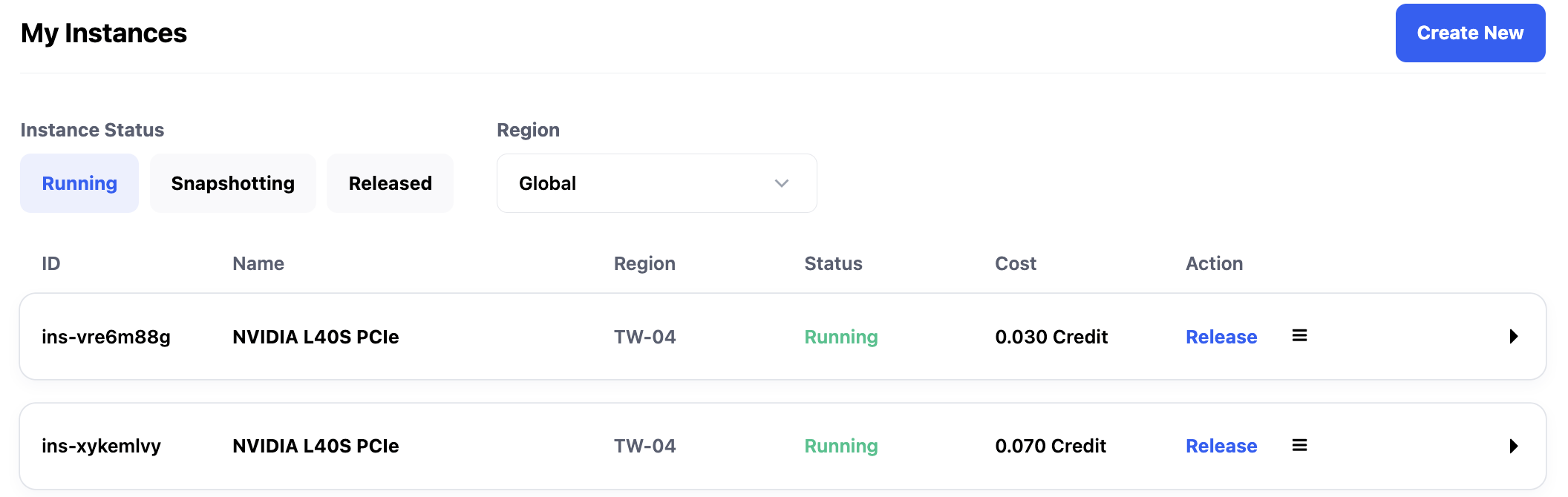
當已啟動實力總數大於等於兩個的時候連續調用該模式,會看到響應頭中的 Deploy-Route-Rule 是隨機變化的。
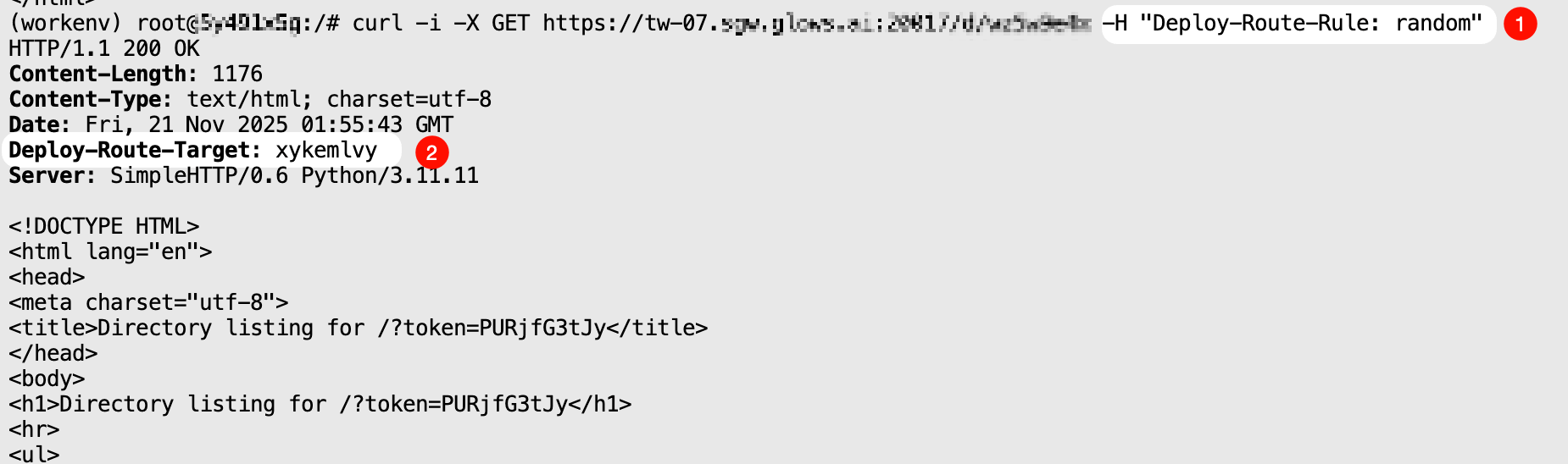
需要注意,如果當前沒有通過該 Auto Deploy 開啟的實例,調用該模式會返回錯誤代碼: {"code": 1006, "msg": "route target not found"}。
round-robin 模式
將請求按順序流轉給已啟動實例,並返回接口調用結果。
curl -i \
-X GET "https://tw-07.sgw.glows.ai:20017/d/xxxxx" \
-H "Deploy-Route-Rule: round-robin"
當已啟動實力總數大於等於兩個的時候連續調用該模式,會看到響應頭中的 Deploy-Route-Rule 是順序變化的。
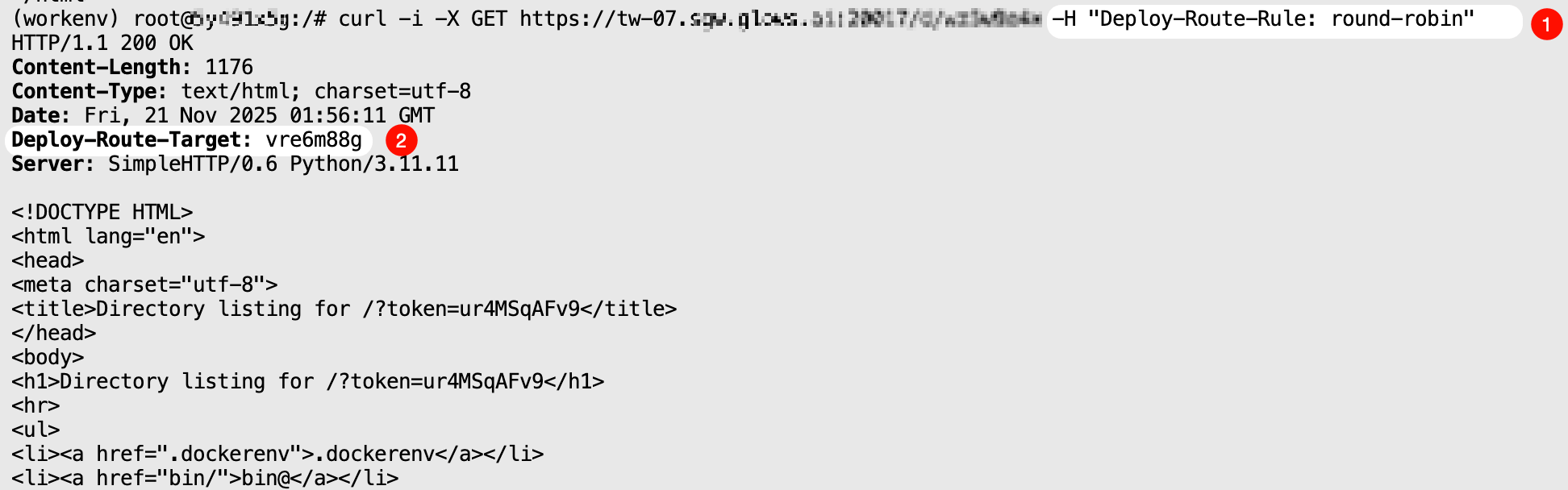
需要注意,如果當前沒有通過該 Auto Deploy 開啟的實例,調用該模式會返回錯誤代碼: {"code": 1006, "msg": "route target not found"}。
{Deploy-Route-Target} 模式
將請求轉發給指定的實例,並返回接口調用結果。
curl -i \
-X GET "https://tw-07.sgw.glows.ai:20017/d/xxxxx" \
-H "Deploy-Route-Rule: xykemlvy"
在一個請求,需要連續調用多個接口處理時,該模式非常有用。
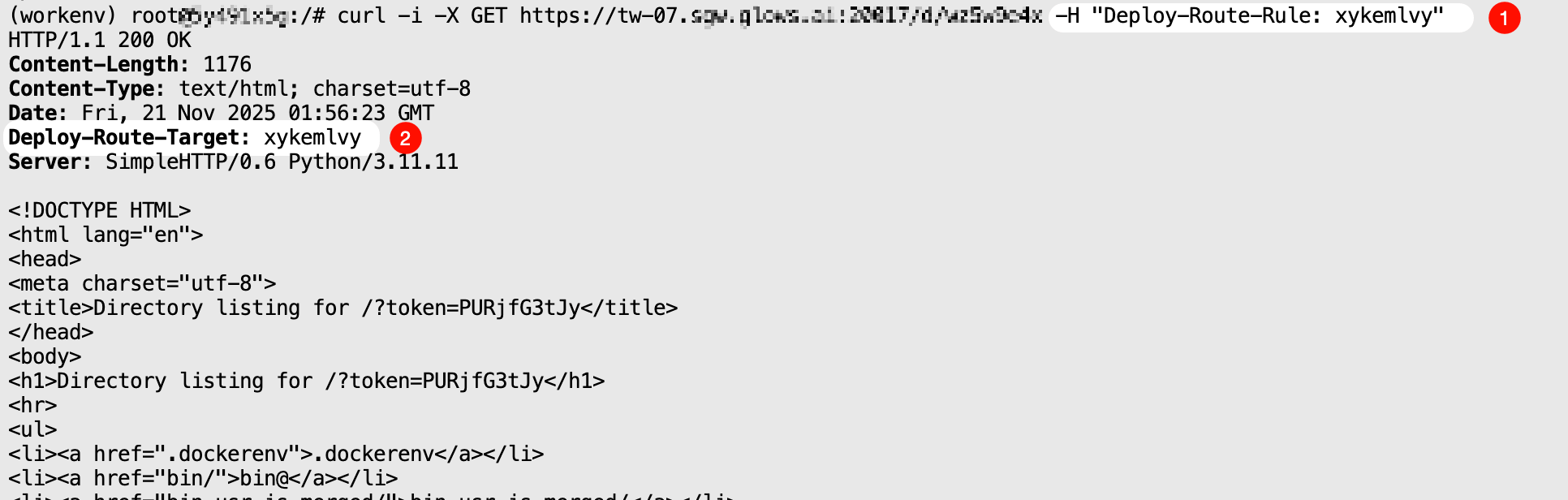
需要注意,如果沒有找到對應 Deploy-Route-Target,調用該模式會返回錯誤代碼:{"code": 1006, "msg": "route target not found"}。
聯繫我們
如果您在使用 Glows.ai 的過程中有任何疑問或者建議,歡迎通過郵件、Discord 或者 Line 聯繫我們。
Email: support@glows.ai
Discord: https://discord.com/invite/glowsai
Line: https://lin.ee/fHcoDgG